0x00 前言
今天给大家介绍的是Linux字典生成工具cewl,并学习更多的高级参数用法。首先先简单的介绍一个cewl工具,该工具最大的功能就能能够爬取网站上的信息并自动生成字典,然后就可以使用该字典配合hydra去进行暴力破解,该工具常用于CTF中攻靶拿Flag使用。OK下面开始进入正题。
0x01 环境需求
cewl需要安装在Linux中使用,我使用的环境事kali Linux
如果使用的是其他Linux版本的系统话,需要使用命令去安装
1 | sodo apt-get install cewl |
命令行运行截图
0x02 参数说明
2.1 可选参数
1 | -h, –help:显示帮助。 |
2.2 认证
1 | –auth_type:Digest或者basic认证。 |
2.3 代理
1 | –proxy_host:代理主机。 |
0x03 实例使用
语法:cewl <url> [options]
3.1 简单用法
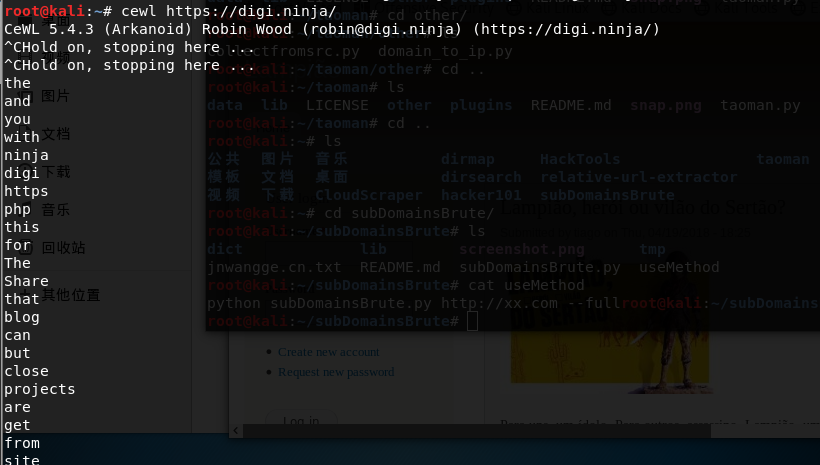
1 | cewl https://xxxx.com |
用法说明:cewl会爬行该网页,抓取网页中的英文字母,没有设置最小字母长度的情况下默认是3,可以使用-m来指定最小单词长度。
##3.2 保存输出结果
将指定长度的结果报错在txt文件中
1 | cewl https://digi.ninja/ -m 5 -w test.txt |
然后输入ls -lh来查看结果文件

使用cat test.txt命令来查看
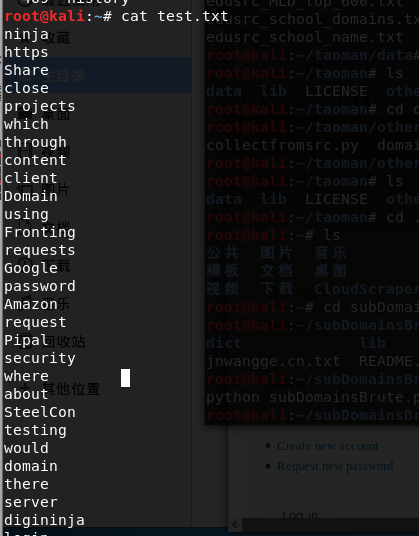
ps:如果该站点的英文单词特别多的话,需要相当一段时间。
然后输入ls -lh来查看结果文件
##3.3 从网站获取email地址
你可以使用-e参数来启用邮件参数,配合-n参数使用,-n参数是在爬行给定网站时隐藏生成的单词列表:
由于刚刚的测试站点上没有email地址,为了能更好的展示出来,换了一个有email地址的网页。结果如下:
1 | cewl 目标站点 -e -n |

3.4 统计网站中单词的重复次数
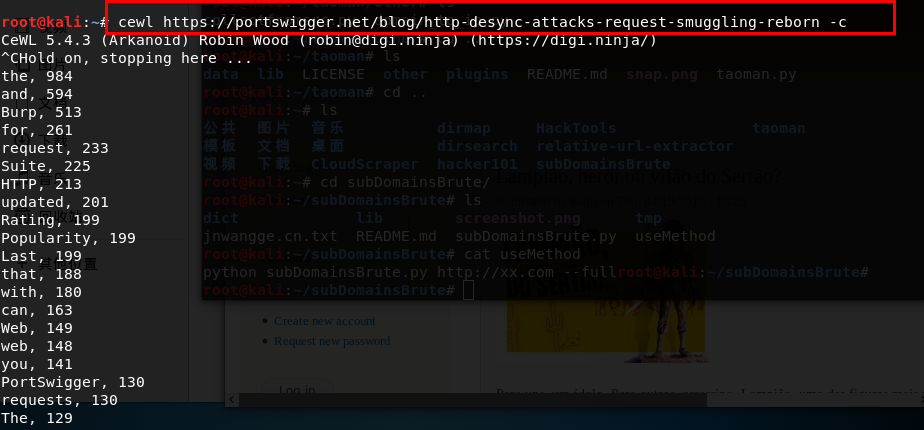
一个英文网站中,不免有很多重复的单词,如果你想统计每个单词的重复次数,可以使用-c命令
3.5 增加爬行深度
如果你想增加爬行等级,来遍历网站中更多的单词来生成更大的字典,你可以使用-d参数,并指定一个爬行深度
等级来进行更加深入的爬行,默认等级是2
1 | cewl https://portswigger.net/blog/http-desync-attacks-request-smuggling-reborn -d 3 |
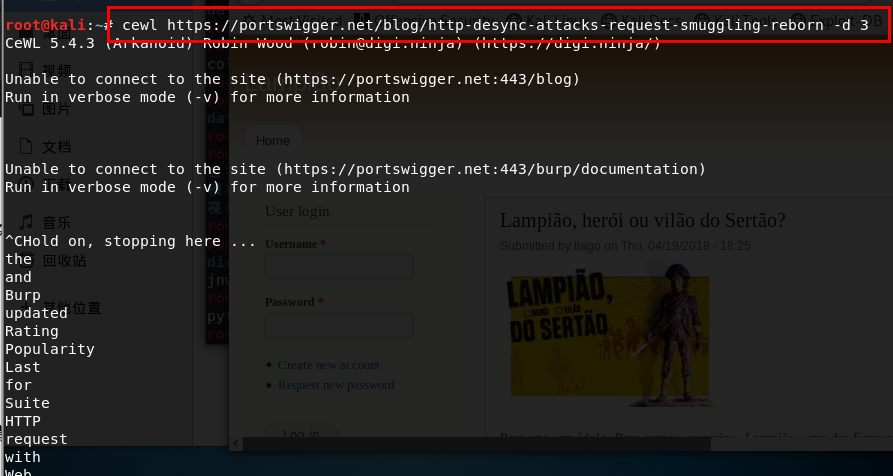
3.6 提取调试信息
你可以使用--debug参数来启用调试模式,显示爬行网站时的错误和原始详细信息:
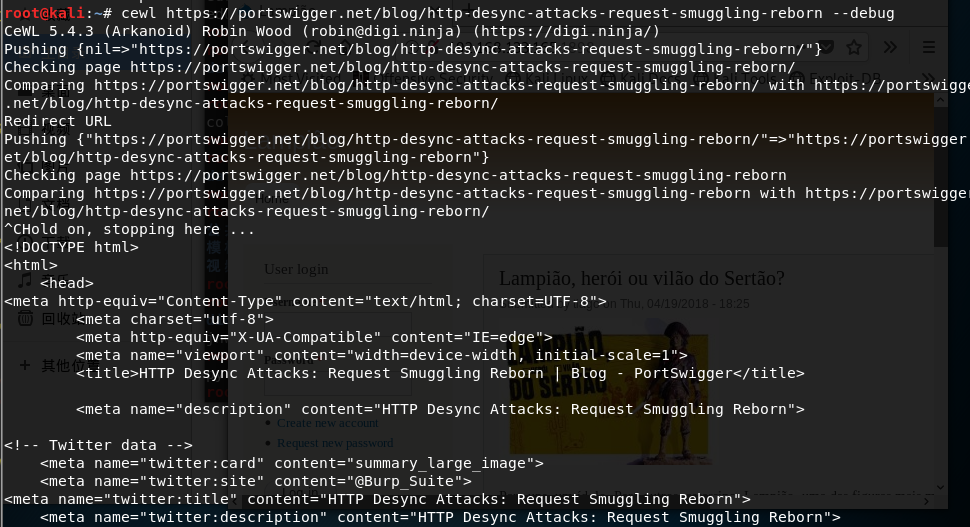
3.7 Verbose模式
为了扩大网站的爬行结果来获取网站更加完整详细的信息,你可以加-v参数,也就是verbose模式。它不会生成字典,而是会dump网站上的信息。
3.8 生成数字字典
如果你想生成字母数字字典,你可以使用—with-numbers参数
1 | cewl http://testphp.vulnweb.com/ --with-numbers |
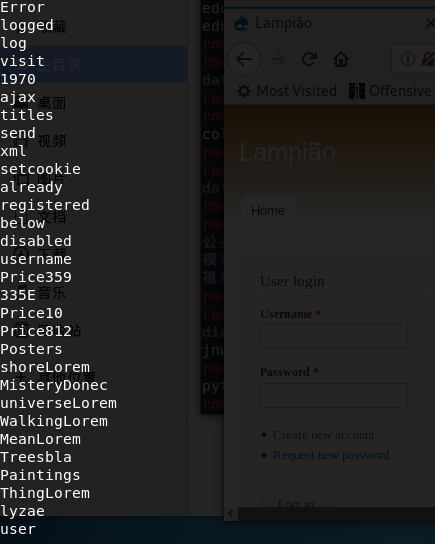
3.9 cewl摘要/基础认证
如果存在一个认证页面来登录网站,那么上面的配置就行不通了,为了生成字典,我们需要使用下面的参数来绕过认证页面:
1 | –auth_type: Digest/basic |
1 | cewl http://192.168.1.105/dvwa/login.php --auth_type Digest --auth_user --用户名 auth_pass 密码 -v |
或者
1 | cewl http://192.168.1.105/dvwa/login.php --auth_type basic --auth_user admin --auth_pass password -v |
3.9 代理URL
如果网站使用了代理服务器,那么cewl的默认命令就无法生成字典了,比如下面这条命令:
1 | cewl -w dict.txt http://192.168.1.103/wordpress/ |
不过你可以使用—proxy参数来开启代理URL,这样就可以生成字典了,比如下列命令:
1 | cewl --proxy_host 192.168.1.103 --proxy_port 3128 -w dict.txt http://192.168.1.103/wordpress/ |
如下图所示,执行第二条命令之后,成功的输出了单词列表:
0x04 参考链接
https://www.4hou.com/tools/14693.html
###

